To get there, however, you may need to put the following into place:
- Development practices such as automated testing;
- Software architectures and component designs that facilitate more frequent releases without impact to users, including feature flags ;
- Tooling such as source code management, continuous integration, configuration management and application release automation software;
- Automation and scripting to enable you to repeatedly build, package, test, deploy, and monitor your software with limited human intervention;
- Organizational, cultural, and business process changes to support continuous delivery.
On hearing about continuous delivery, some people's first concern is that it implies that quality standards will slip or that the team will need to take shortcuts in order to achieve these frequent releases of software.
The truth is quite the opposite. The practices and systems you put in place to support continuous delivery will almost certainly raise quality and give you additional safety nets if things do go wrong with a software release.
Your software will still go through the same rigorous stages of testing as it does now, potentially including manual QA testing phases. Continuous delivery is simply about allowing your software to flow through the pipeline that you design, from development to production, in the most rigorous and efficient way possible.
The Key Building Block of Continuous Delivery: Automation!
Though it is quite valid and realistic to have manual steps in your continuous delivery pipeline, automation is central in speeding up the pace of delivery and reducing the cycle time.
After all, even with a well resourced team, it is not viable to build, package, compile, test, and deploy software many times per day by hand, especially if the software is in any way large and complex.
Therefore, the overriding aim should be to increasingly automate away more of the pathway between the developer and the live production environment. Here are some of the major areas you should focus your automation efforts on:
Automated Build & Packaging
The first thing you will need to automate is the process of compiling and turning developers' source code into deployment-ready artifacts.
Though most software developers make use of tools such as Make, Ant, Maven NuGet, npm, etc. to manage their builds and packaging, many teams still have manual steps that they need to carry out before they have artifacts that are ready for release.
These steps can represent a significant barrier to achieving continuous delivery. For instance, if you release every three months, manually building an installer is not too onerous. If you wish to release multiple times per day or week however, it would be better if this task was fully and reliably automated.
| Aim To: |
| Implement a single script or command that enables you to go from version controlled source code to a single deployment ready artifact. |
Automated Builds & Continuous Integration
Continuous integration is a fundamental building block of continuous delivery.
It involves combining the work of multiple developers and continually compiling and testing the integrated code base such that integration errors are identified as early as possible.
Ideally, this process will make use of your automated build so that your continuous integration server is continually emitting a deployment artifact containing the integrated work of the development team, with the result of each build being a viable release candidate.
Typically, you will set up a continuous integration server or cloud service such as Jenkins, TeamCity, or Team Foundation Server, carrying out the integration many times per day.
Third party continuous integration services such as CloudBees DEV@cloud, Travis CI, or CircleCI can help to expedite your continuous delivery efforts. By outsourcing your continuous integration platform, you are free to focus on your continuous delivery goals, rather than on administration and management of tools and infrastructure.
| Aim To: |
| Implement a continuous integration process that continually outputs a set of deployment-ready artifacts. |
| Evaluate cloud-based continuous integration offerings to expedite your continuous delivery efforts. |
| Integrate a thorough audit trail of what has changed with each build through integration with issue tracking software such as Jira. |
Your continuous integration tooling will likely be central for your continuous delivery efforts. For instance, it can go beyond builds and into testing and deployment. For this reason, continuous integration is a key element of your continuous delivery strategy.
Automated Testing
Though continuous delivery can (and frequently does) include manual exploratory testing stages performed by a QA team, or end user acceptance testing, automated testing will almost certainly be a key feature in allowing you to speed up your delivery cycles and enhance quality.
Usually, your continuous integration server will be responsible for executing the majority of your automated tests in order to validate every developer check-in.
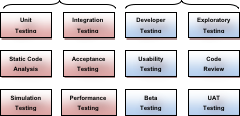
However, other automated testing will likely subsequently take place when the system is deployed into test environments, and you should also aim to automate as much of that as possible. Your automated testing should be detailed , testing multiple facets of your application:
| Test Type |
To Confirm That: |
| Unit Tests |
Low level functions and classes work as expected under a variety of inputs. |
| Integration Tests |
Integrated modules work together and in conjunction with infrastructure such as message queues and databases. |
| Acceptance Tests |
Key user ows work when driven via the user interface, regarding your application as a complete black box. |
| Load Tests |
Your application performs well under simulated real world user load. |
| Performance Tests |
The application meets performance requirements and response times under real world load scenarios. |
| Simulation Tests |
Your application works in device simulation environments. This is especially important in the mobile world where you need to test software on diverse emulated mobile devices. |
| Smoke Tests |
Tests to validate the state and integrity of a freshly deployed environment. |
| Quality Tests |
Application code is high quality – identified through techniques such as static analysis, conformance to style guides, code coverage etc. |
Ideally, these tests can be spread across the deployment pipeline, with the slower and more expensive tests occurring further down the pipeline, in environments that are increasingly production-like as the release candidate looks increasingly viable. The aim should be to identify problematic builds as early as possible in order to avoid re-work, keep the cycle time fast and get feedback as early as possible:
| Aim To: |
| Automate as much of your testing as possible. |
| Provide good test coverage at multiple levels of abstraction against both code artifacts and the deployed system. |
| Distribute di erent classes of tests along your deployment pipeline, with more detailed tests occurring in increasingly production-like environments later on in the process, while avoiding human re-work. |
Automated tests are your primary line of defense in your aim to release high quality software more frequently. Investing in these tests can be expensive up front, but this battery of automated tests will continue to pay dividends across the lifetime of the application.
Automated Deployments
Software teams typically need to push release candidates into different environments for the different classes of testing discussed above.
For instance, a common scenario is to deploy the software to a test environment for human QA testing, and then into some performance test environment where automated load testing will take place. If the build makes it through that stage of the testing, the application might later be deployed to a separate environment for UAT or beta testing.
Ideally, the process of reliably deploying an arbitrary release candidate, as well as any other systems it communicates with, into an arbitrary environment should be as automated as possible.
If you want to operate at the pace that continuous delivery implies, you are likely to need to do this many times per day or week, and it's essential that it works quickly and reliably.
Application release automation tools such as XebiaLabs’ XL Deploy can facilitate the process of pushing code out to environments. XL Deploy can also provide self-service capabilities that allow teams to pull release candidates into their environments without requiring development input or having to create change tickets or wait on middleware administrators.
This agility in moving software between environments in an automated fashion is one of the main areas where teams new to continuous delivery are lacking, so this should also be a key focus in your own preparations for continuous delivery.
| Aim To: |
| Be able to completely roll out an arbitrary version of your software to an arbitrary environment with a single command. |
| Incorporate smoke test checks to ensure that your deployed environment is then valid for use. |
| Harden the deploy process so that it can never leave environments in a broken or partially deployed state. |
| Incorporate self-service capabilities into this process, so QA staff or business users can select a version of the software and have that deployed at their convenience. In larger organizations, this process should incorporate business rules such that specific users have deployment permissions for specific environments. |
| Evaluate application release automation tools in order to accelerate your continuous delivery e orts. |
Managed Infrastructure & Cloud
In a continuous delivery environment, you are likely to want to create and tear down environments with much more flexibility and agility in response to the changing needs of the project.
If you want to start up a new environment to add into your deployment pipeline, and that process takes months to requisition hardware, configure the operating system, configure middleware, and set it up to accept a deployment of the software, your agility is severely limited and your ability to deliver is impacted.
Taking advantage of virtualization and cloud-based offerings can help here. Consider cloud hosts such as Amazon EC2, Microsoft Azure or Google Cloud Platform to give you flexibility in bringing up new environments and new infrastructure as the project dictates.
Cloud can also obviously make an excellent choice for production applications, giving you more consistency across your development and production environments than previously achieved.
| Aim To: |
| Cater for exibility to your continuous delivery processes so you can alter pipelines and scale up or down as necessary. |
| Implement continuous delivery infrastructure in the cloud, giving you agility in quickly rolling out new environments, and elasticity to pause or tear down those environments when there is less demand for them. |
Infrastructure As Code
A very common class of production incidents, errors, and rework happens when environments drift out of line in terms of their configuration, for instance when development environments start to differ from test, or when test environments drift out of line with production.
Configuration management tools such as Puppet, Chef, Ansible, or Salt and environment modeling tools such as Vagrant or Terraform can help you avoid this by defining infrastructure and platforms as version controlled code, and then having the environments built automatically in a very consistent and repeatable way.
Combined with cloud and outsourced infrastructure, this cocktail allows you to deploy accurately configured environments with ease, giving your pace of delivery a real boost.
Vagrant and Terraform can also help here, giving developers very consistent and repeatable development environments that can be virtualized and run on their own machines. Container frameworks (see next section) are another popular option to achieve this.
These tools are all important because consistency of environments is a huge enabler in allowing software to flow through the pipeline in a consistent and reliable way.
| Aim To: |
| Implement con guration management tools, giving you much more control in building environments consistently, especially in conjunction with the cloud. |
| Investigate Vagrant, Terraform and container frameworks as a means of giving developers very consistent local development environments. |
Container Frameworks
One way or another, containers will very likely crop up at some point in your continuous delivery preparation: whether as a new runtime for your production environment, a more lightweight means of creating a reproducible local development setup, or simply as a technology to track for potential future use.
If you decide to try to containerize your applications, ensure you also investigate orchestration frameworks such as Docker Swarm, Mesos, or Kubernetes, which will allow you to define and control groups of related containers as a single, versioned entity. Since these frameworks are still “rough around the edges” in places, optionally also look one of a variety of management tools such as Deis, Rancher, or OpenShift, to simply usage.
Should you be planning to run your production environment on containers, ensure that the orchestration framework you choose can be used for local development, too. Otherwise, there is, again, a risk that the way containers are “linked up” on a developer’s machine will not match what will happen in production.
Automated Production Deployments
Though most software teams have a degree of automation in their builds and testing, the actual act of deployment onto physical production servers is often still one of the most manual processes for the typical software team.
For instance, teams might have multiple binaries that are pushed onto multiple servers, some database upgrade scripts that are manually executed, and then some manual installation steps to connect these together. Often they will also carry out manual steps for the startup of the system, and smoke tests.
Because of this complexity, releases often happen outside of business hours. Indeed, some unfortunate software teams have to perform their upgrades and scheduled maintenance at 3am on a Sunday morning in order to cause the least disruption to the customer base!
To move towards continuous delivery, you'll need to tackle this pain and slowly script and automate away the manual steps from your production release process such that it can be run repeatedly and consistently. Ideally, you will need to get to the stage where you can do this during business hours while the system is in use. This may have significant consequences for the architecture of your system.
To make production deploys multiple times per day whilst the system is in use, it's important to ensure that the process is also tested and hardened so you never leave the production application in a broken state due to a failed deploy.
| Aim To: |
| Completely automate the production deploy process such that it can be executed from a single command or script. |
| Be able to deploy the next version of the software while the production system is live, and switch over to the new version with no degradation of service. |
| Be able to deploy to production using exactly the same process by which you deploy to other environments. |
| Implement the best practices described below, such as canary releasing, rollback, and monitoring in order to enhance stability of the production system. |