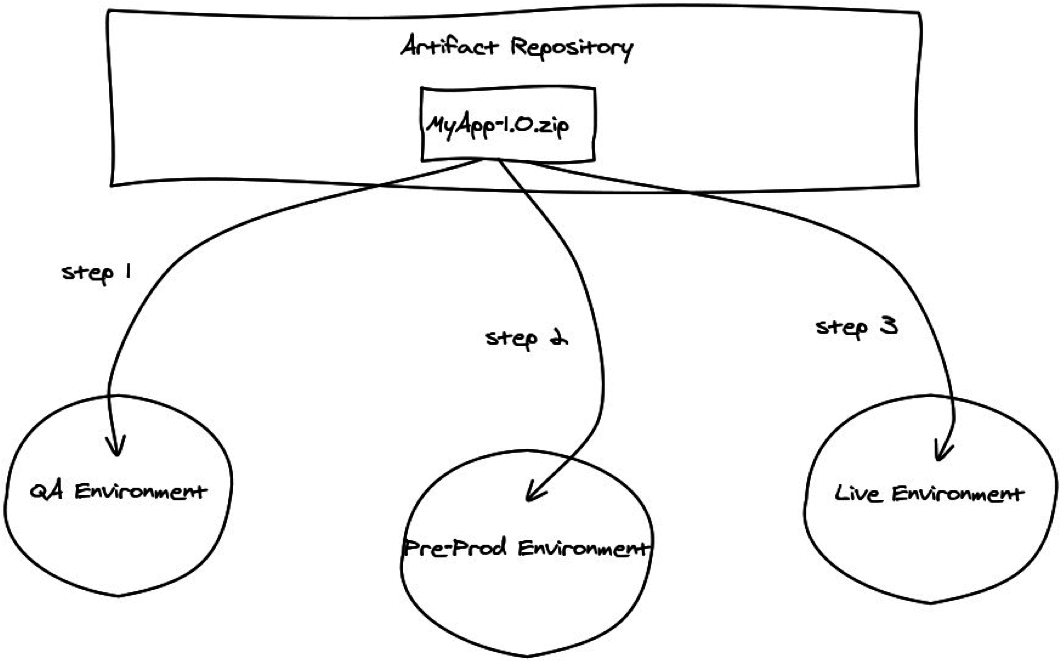
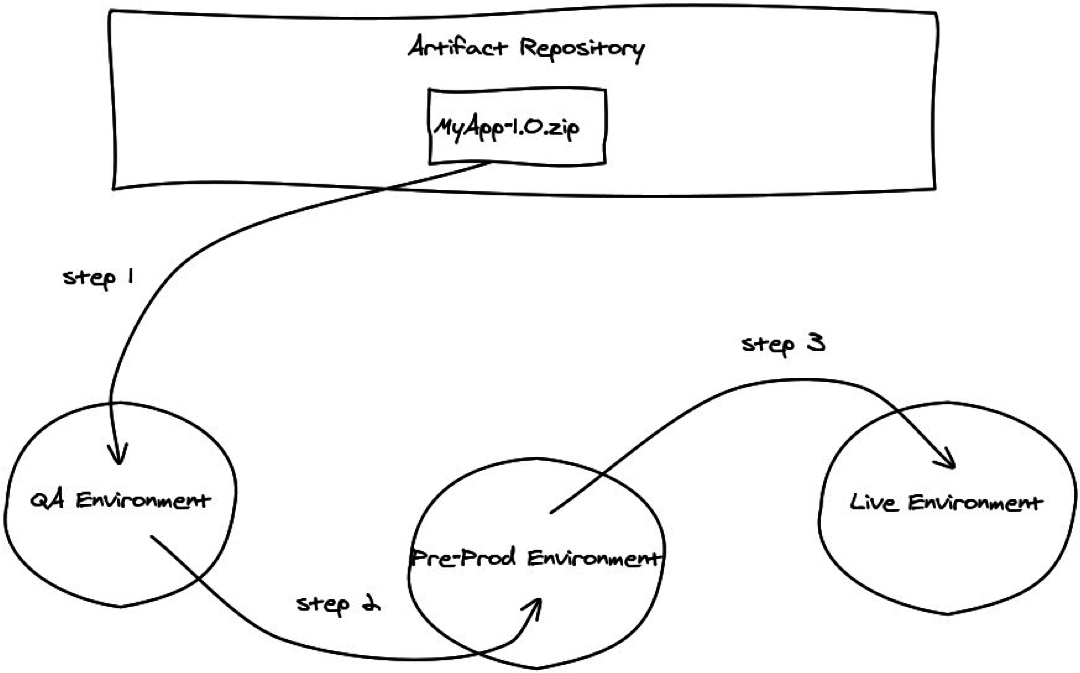
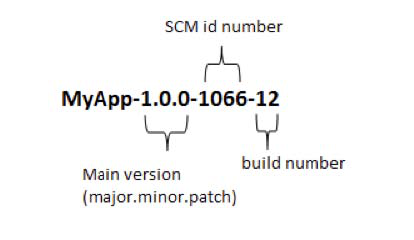
PATTERN: Automated deployments using tools and scripts
ANTI-PATTERN: Manual deployments by hand
It's too much to expect a person to manually deploy a complex software solution to an equally complex production environment time after time and never make a mistake. The odd mishap is what makes us human. So let's leave the machines to do the stuff they're good at: the repetitive, labor intensive tasks – tasks like deploying software!
So the first good practice is to automate software deployments. In its most simple form this could mean simply writing a script to perform the deployments, or using a specific tool to do the leg-work for you.
But what about the environment we're deploying our applications on? How do they get deployed? If we're deploying our infrastructure changes by hand, then we're not fully leveraging the power of deployment automation.
Automating deployments brings with it a heap of other benefits as well, such as increased speed, greater reliability, and built-in audit trails. These benefits can be built into your automated software deployments with very little effort for maximum reward.
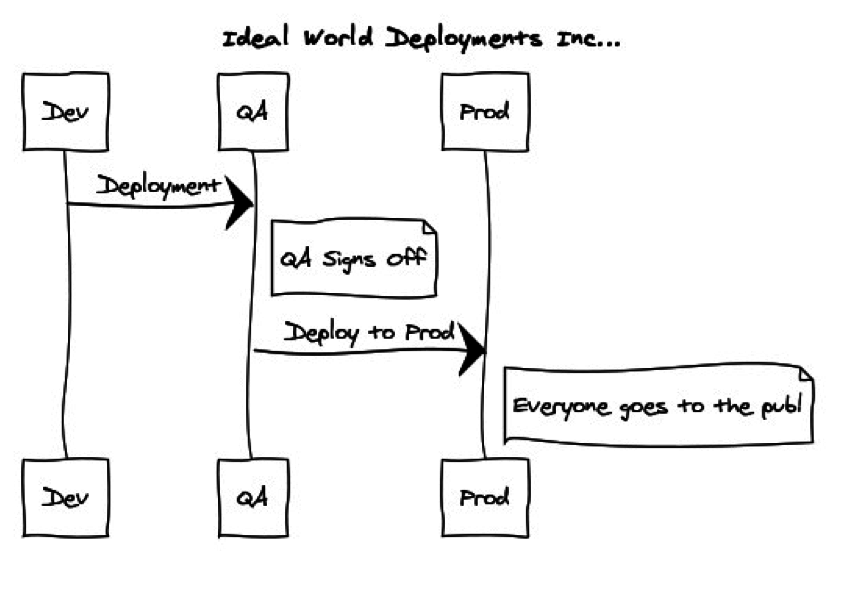
Figure 1 Automation lies at the center of good deployment practice
Why Should I Script It?
I know, it's simple. You could do it in your sleep, there's no need to write a script to do it, is there? Yes, there is.
Let's say you're deploying a jar file to a directory and changing a line in a config file. That's simple enough to do! But if you're doing it manually, then it's also simple enough to get it completely wrong. It's called human error and the best thing about it is you don't even know you're doing it.
Scripting your deployments gives you a nice cookie trail of what you've just done, so if things do go awry, you can look at the script and step through it. You can't replay and step through random human errors!
You can use just about any scripting language to script your software deployments, but again there are some good practices which should be brought into consideration.
- Verbosity – You probably don't want to have to read the world's most verbose scripts when you're troubleshooting your deployments.
- Clarity/readability – Pick a language that's readable and not ambiguous.
- Support – First thing you do when your script gives you an error? Google it, of course! The bigger the support community, the better (sometimes).
- Personal taste – never overlook people's personal taste when it, comes to choosing a scripting language. If the whole team want to use perl, then maybe they will just feel a lot happier using perl!
Here's an example of a simple task which is quite commonly done at the beginning of a deployment – working out the free disk space. Three different scripting languages provide 3 fairly different scripts:
Each script varies in its relative complexity and verbosity, and the output is subtly different from each one. In this very basic example, the Ruby script requires more effort to setup and write, while the shell script is very straightforward. However, deployment scripts are a lot more complex than this, and a slightly more elegant language like Ruby might come into its own depending on the requirements. Ultimately you need to choose a scripting language which is fit for purpose and which the users feel most comfortable with.
Automating Infrastructure Deployments
Deploying servers can be an onerous and highly manual task. Or you could automate it and make it a simple manual one! Thankfully, there are a number of tools available to help us do this. VMware is a popular choice of virtualisation software, and can be used to deploy and configure anything from individual vms, to large vm farms. PowerCLI is a command line tool which allows us to automate these tasks. There's a wealth of information, code snippets and examples in the communities to help get you up and running. Here's an example of how to deploy a number of VMs from a single template, and apply some guest customizations:
The script reads from a CSV file containing information such as the host to deploy to, the new vm name to use, the guest customization to apply and the template to use. The CSV file will look similar to this:
The guest customization script can do numerous basic tasks such as setting time zones and registering the VM on a domain. However, we can automate even further to perform tasks such as installing software by using the PowerCLI script to invoke another script that resides on the template, and passing in relevant vm-specific parameters using PowerCLIs Invoke-VMscript.
If VMware and PowerCLI are good tools for vm deployment, then tools such as Chef, puppet and CfEngine are great for configuring them. The question should not be whether or not to use them, rather, which one should I use?
Chef, Puppet and CFengine all provide automated scripted solutions for deploying applications, policies, accounts, services etc to your servers. Their underlying similarity is that they provide users with a centralised system for managing and deploying server configurations on top of your VM.
While the likes of CFengine, Chef and Puppet are focused on configuration, tools such as JumpBox, Capistrano and Fabric are geared more specifically to application deployment. The one thing they share in common is that they all provide automated solutions.
Continuous Delivery and DevOps
With scripted, automated deployments we can expand our traditional continuous integration system to include software delivery. If our build passes all the unit tests then we can deploy it to a test environment, and with automated infrastructure deployments, we can even provision those environments automatically. Continuous delivery is the logical extension of continuous integration – if a build passes all the tests on the QA environment, then it's automatically deployed to a UAT environment. If it passes all the tests there, it could be automatically deployed to production. This system is only made possible with automated deployments. The workflow of builds moving from dev all the way through to production can be imagined as a pipeline – indeed, continuous delivery and release pipelines are becoming increasingly frequent bed-partners. Here's an example of a build pipeline in a continuous delivery system:
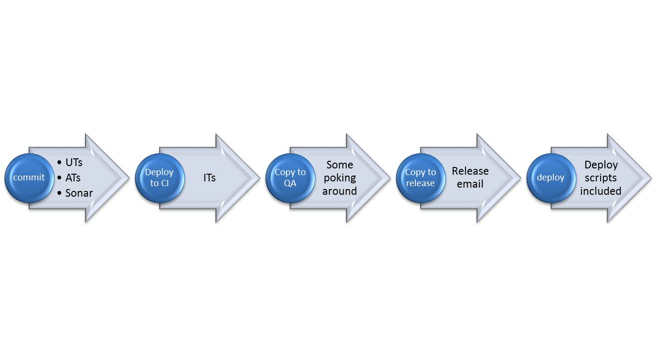
One of the key attributes in this system is the visible progression of a release from one stage (or environment) to the next. This is akin to a release workflow management process. As the build progresses along the pipeline, from left to right in the picture above, the release moves from development, through QA and UAT and into the hands of the Operations team. It's a seamless progression with no manual handover, and so the development and operations groups must be tightly coupled. This is the foundation of the DevOps movement – breaking down the traditional barriers between development and operations, and once again, automation is at the heart of it!
Naturally a number of tools are available to support this workflow. Their key attributes are:
- Workflow management
- Build tracking/pipelines
- Environment management/procurement
- Reporting
- Auditing
- Artifact management
Tools like Thoughtworks' Go provide much of the functionality mentioned above, but Go is generally focussed on Continuous Integration. The pipeline visualisation provides a certain degree of workflow management and the environment management functionality provides a one-stop-shop for tracking which agents are assigned to particular environments. Go actively encourages collaboration between development and operations; it's designed to be a central tool for developers and operations staff alike – for the developer it provides state of the art (CI) (with all the usual trimmings of test reporting, build metrics and so on) and for the Operations team it provides a good environment management interface, release tracking, and a simple UI for doing deployments (which can literally be just a click of a button).
Jenkins is another application which has expanded from a Continuous Integration tool to being more DevOps focussed. Like Go, it caters to both Development and Operations alike. It has one of the friendliest and most functional CI systems around, but the plugins offer so much more. There are plugins which hook into the Amazon EC2 or the Ubuntu Enterprise Cloud, to allow you to start nodes on demand (there are also plugins for VMware and VirtualBox in case you manage your own vm farm/cloud). There are also pipeline and workflow plugins to help you manage your complex build workflows. The list of plugins goes on and on.
Electric Cloud's ElectricDeploy is a purpose built software delivery tool which firmly embraces the DevOps culture. It enforces and builds on automated solutions to ensure consistency and visibility across the whole application delivery lifecycle:
- Uses application and environment models to ensure consistent deployments across all environments
- Focuses on failure management (allows users to configure success/failure thresholds etc.)
- Provides visibility to all users & teams
- Leverages the Pipeline concept
- Is infrastructure agnostic (works for physical, virtual or cloud infrastructure)
This space is likely to become rich with enterprise tools as the DevOps movement gathers pace. Their key features are likely to be built on:
- collaboration between teams
- breaking down traditional barriers
- a focus on automation
- continuous delivery
- high visibility