The Node.js architecture can be divided into two main objectives: (1) handling events of interest using the event loop and (2) executing JavaScript on a server rather than in a browser. Prior to understanding these ideas, though, it is essential to understand the differences between synchronous and asynchronous programming.
Synchronous vs. Asynchronous Programming
The main difference between synchronous and asynchronous programming is how each deals with a blocking operation, where a task takes a non-trivial amount of time to complete or waits on external input to complete (which may never come and, therefore, the task may never complete). In synchronous programming, the thread that handles the task blocks and waits for the task to complete before doing any more work. In asynchronous programming, the thread delegates the work to another thread (or the operating system) and continues executing the next instruction. When the background thread completes the task, it notifies the original thread, allowing the original thread to handle the now-completed task.
These differences can be illustrated using an analogy. Suppose a restaurant has a kitchen, a bar, and one waitress. Since the waitress has numerous tables to serve, she cannot take drink orders from a table and wait at the bar until the drinks are done before taking food orders for the table. Likewise, the waitress cannot wait at the kitchen until a submitted food order is completed before serving another table. Instead, the waitress takes drink orders, and if ready, food orders for a table, gives the bartender the drink order, and gives the kitchen the food order. She then proceeds to serve the next table, repeating this process for each table she must serve.
Between providing the bartender with new drink orders, the waitress checks to see if any drink orders have been fulfilled. If there are fulfilled orders, she takes the drinks to the table that ordered them. Likewise, if the kitchen has completed a food order, the waitress takes the food to the table that ordered it. Although there is only one waitress, she is able to simultaneously serve multiple tables because she offloads time-consuming work to the bartender and the kitchen and does not block, waiting for an order to be fulfilled. When either the bartender or the kitchen completes an order, she handles the completed order by bringing it to the table that made the order.
This is asynchronous programming in action. Had the waitress instead taken drink orders and waited at the bar for the order to be completed before returning to the table to take food orders, she would have been operating synchronously. In the case of Node.js, an event loop (akin to the waitress) is used to cyclically check worker threads or the operating system (akin to the bar or the kitchen) to see if offloaded work has been completed. This helps ensure that performing a blocking operation in Node.js does not bring the system to a halt until the operation completes.
The Event Loop
Unlike many large-scale frameworks, Node.js application code executes using a single thread. Instead of creating a series of threads and assigning each a task, Node.js uses an event loop, allowing a developer to register callback functions to execute when an event of interest occurs. For example, instead of creating a new thread to block and handle each HTTP request received by the server, a developer registers a function with the Node.js framework that Node.js uses to handle the request. This allows Node.js to asynchronously execute the callback function whenever it deems most effective.
This scheme has many important advantages, including:
- The developer is not responsible for handling the nuances of multithreading, such as deadlock avoidance and race conditions.
- It is possible to make non-blocking IO calls, or if desired, block with a handful of timer-based APIs.
- Callbacks encapsulate the complete logic for handling an event, allowing Node.js to queue the handling logic to be executed when most effective.
The core of the Node.js event-driven architecture is the event loop, illustrated below.
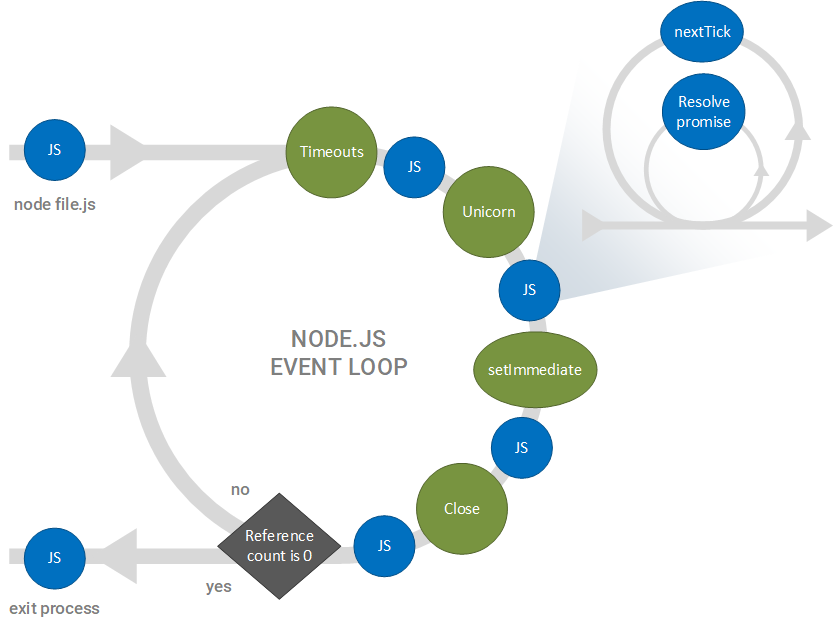
Node.js event loop starts by processing a single JavaScript file, which in turn registers callbacks for its events of interest. For each callback function registered, a reference counter is incremented, allowing Node.js to track how many callbacks are still left to be executed.
As the event loop proceeds, it executes each step, or phase, in the loop (the green and blue circles), handling each of the events associated with each phase. Once the callback reference count reaches 0, the event loop exits and the Node.js process terminates. If the reference count is greater than 0 at the end of a loop iteration, the loop executes again. Commonly, the reference count will not decrement to 0, and thus, Node.js will continue handle events (such as HTTP requests) indefinitely, unless the process is manually terminated.
Event Loop Phases
The green circles in the event loop represent Node.js code that is executed, while the blue circles represent application code that is executed in response to events that occur within the Node.js code. For example, the Timeout phase represents the Node.js code that is executed to find timer events that have expired. Once these events have been collected, the blue application code is executed to handle these timeout events.
The four phases of the event loop are:
- Timeout: Checks to see if any timeouts have occurred (i.e. registered using the
setTimeout or setInterval functions). For example, if a timer is set in application code for 200 ms and at least 200 ms has expired since the initiation of the timer, the timer is declared expired; once the expired timers have been queued, the callback associated with each timer is executed. This process continues until all expired timers have been handled.
- Unicorn: IO events, such as completed file system and network events, are handled. This process continues until all IO events for which callbacks have been registered have been handled.
-
setImmediate : Events declared via the setImmediate function in the previous loop iteration are executed. This process continues until all setImmediate callback functions have been executed.
- Close: Internal clean-up is executed (i.e. closing sockets) and any callbacks associated with these events are executed. This process continues until all associated callbacks have been executed.
Once all of the callbacks associated with the Close phase have been executed, the callback reference count is checked. If the count is greater than 0, the loop is repeated; if the reference count equals 0, the loop is exited and the Node.js process is terminated.
Resolved Promises and nextTicks
Within each of the application code steps (blues circles), all callbacks — called promises in this context — are executed and all callback functions registered using the nextTick function are executed. Once all registered promises and nextTick callbacks have been completed, the user code circle is exited and the next phase of the event loop is entered.
Note that promises and nextTick callbacks are executed in a sub-loop, as promises and nextTick callbacks can introduce more callbacks to be executed in order to handle the current promise or nextTick callback. For example, recursively calling nextTick within a nextTick callback will queue up a callback that must be completed before execution of the event loop can continue. Note that developers should be wary of making recursive nextTick calls, as this may starve the event loop, not allowing the next callback to be completed or next phase of the loop to be entered. See the documentation on understanding nextTick for more information.
One of the unfortunate blunders in Node.js is the naming of the nextTick and setImmediate functions (see the morning keynote at Node.js Interactive Europe 2016 for more information). The former is used to execute the supplied callback at the completion of the current callback, while the latter is used to defer the execution of the supplied callback until the next iteration of the event loop.
Many developers rightfully confuse these functions, reasoning that tick represents an iteration of the event loop and therefore, next tick is the next iteration. Likewise, immediate is often inferred to mean the current callback, and hence, the callback supplied to setImmediate is assumed to be completed immediately following the current callback. While understandable, this is not how Node.js works. Although this misnomer has been a known problem since the early days of Node.js, the frequent use of both functions in application code has precluded renaming these functions.
Developers should, therefore, be careful not to confuse the use of these two functions and accidently apply them in the reverse manner.
async and await
Although promises allow for deferred, non-blocking execution, they also have a major disadvantage: They are syntactically scrupulous when chained. For example, creating a chain of promises in Node.js (or JavaScript in general) results in code that resembles the following:
Asynchronous chains such as these (disparagingly referred to as the pyramid of doom) can be lead to unreadable code and difficult to debug applications. With the advent of version 5.5 of the V8 JavaScript engine (see below) in October 2016, Node.js applications can now utilize the async and await keywords introduced in JavaScript ES2017. This allows the above code to be reduced to the following:
The use of the async keyword creates an asynchronous function that removes much of the boilerplate code and repetition required for the resolution of promises. Within asynchronous functions, the await operator can be used to wait for a promise to be resolved and return its resolved value. In the snippet above, response1 is not assigned until the promise associated with someObject.call() resolves, after which the response1 is assigned the value of the resolved someObject.call() promise. Likewise, anotherObject.call(response1) is not executed until response1 has been assigned after the resolution of someObject.call() . If any of the awaited functions throws an error (which was previously caught using the .catch(...) syntax), the catch clause of the try-catch block will handle the error (since the await operator throws any errors received when resolving the promise it is awaiting on).
It is important to note that the above code, although seemingly asynchronous, is actually asynchronous. The await operator simply abstracts an underlying promise (e.g. one returned from someObject.call()) and allows code to be written to handle asynchronous code in a seemingly synchronous manner.
Server-Side JavaScript
The second key to the success of Node.js is that developers write Node.js server applications in JavaScript. This allows developers to write server-side applications in the same language in which they are accustomed to writing client-side applications. Apart reducing the learning curve, this allows developers to reuse portions of client code in server applications and vice-versa.
The V8 JavaScript Engine
The ability of Node.js to execute JavaScript on the server is achieved by deploying the Chrome V8 JavaScript engine in a standalone environment rather than within the confines of a browser. While JavaScript engines are often relegated to browsers in order to interpret and execute JavaScript code retrieved from a server, Node.js incorporates the V8 JavaScript engine to execute JavaScript in any environment that supports Node.js, as illustrated in the figure below.
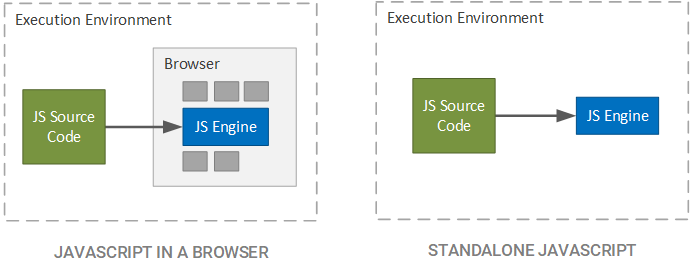
The Node.js Stack
Since the V8 JavaScript engine is written in C++, Node.js includes a binding layer that allows application code to be written in JavaScript but execute natively through the JavaScript engine. Above the binding layer, Node.js includes an API layer — written in JavaScript — providing core functionality, such as managing sockets and interfacing with the file system through Node.js (see the list of Node.js APIs below for more information). At the top of the stack, developers create applications using the Node.js API layer in conjunction with third-party libraries and APIs.
Along with the V8 JavaScript engine, Node.js also includes the Unicorn Velociraptor Library (libuv), which houses the Node.js event loop and the internal mechanisms used to process registered callback functions. Node.js also includes a set of supporting libraries that allow Node.js to perform common operations, such as opening a socket, interfacing with the file system, or starting an HTTP server. While libuv and the Node.js supporting libraries are written in C++, their functionality can be accessed by Node.js applications using the API and bindings layer, as illustrated below.

Isomorphic Javascript
The ability of Node.js to render JavaScript on the server has created a natural extension in web development: Isomorphic JavaScript. Sometimes termed universal JavaScript, isomorphic JavaScript is JavaScript that can run on both the client and the server. In the early days of webpages, static Hypertext Markup Language (HTML) pages were generated by the server and rendered by the browser, providing a simplified User Experience (UX). While these webpages were slow to render, since a single click required the loading of an entirely new page, Search Engine Optimization (SEO) was straightforward, requiring that SEO crawlers parse a static HTML page and follow anchored links to obtain a mapping of a website.
As JavaScript was introduced to the client and rendered by the browser, Single-Page Applications (SPAs) became the de-facto standard. Compared to static webpages, SPAs allow users to quickly and seamlessly transition from one page to another, requiring that only JavaScript Object Notation (JSON) or eXtensible Markup Language (XML) data be transferred from the server to the client, rather than an entire HTML page. While SPAs do have many speed and UX advantages, they commonly require an upfront load time (which is usually accompanied by a loading message) and are difficult to tune for SEO, since crawlers can no longer obtain a static view of a page without rendering a large portion of the SPA themselves.
Isomorphic JavaScript is a happy-medium between these two extremes. Instead of performing all of the page generation on the server or all on the client, applications can be run on both the client and the server, providing for numerous performance optimizations and SEO tunings. Companies such as Twitter have even gone so far as to reduce initial load times to 1/5 of those experienced with client-only rendering by offloading the generation of webpages to the server, removing the need for the client to load the entire SPA before rendering the first page displayed to users. Apart from performance and SEO improvements, isomorphic JavaScript allows developers to share code between the client and server, reducing the logical duplication experienced when implementing many large-scale web applications (such as domain and business logic being written in one language on the server and repeated in another language in the SPA). For more information, see Isomorphic JavaScript: The Future of Web Apps by Spike Brehm (of Airbnb).
