MongoDB is a document-based NoSQL database that bridges the gap between scalable key-value stores like Datastore and Memcache DB, and RDBMS's querying and robustness capabilities. Some of its main features include:
- Document-oriented storage - data is manipulated as JSON-like documents
- Querying - uses JavaScript and has APIs for submitting queries in every major programming language
- In-place updates - atomicity
- Indexing - any attribute in a document may be used for indexing and query optimization
- Auto-sharding - enables horizontal scalability
- Map/reduce - the MongoDB cluster may run smaller MapReduce jobs than a Hadoop cluster with significant cost and efficiency improvements
MongoDB implements its own file system to optimize I/O throughput by dividing larger objects into smaller chunks. Documents are stored in two separate collections: files containing the object meta-data, and chunks that form a larger document when combined with database accounting information. The MongoDB API provides functions for manipulating files, chunks, and indices directly. The administration tools enable GridFS maintenance.
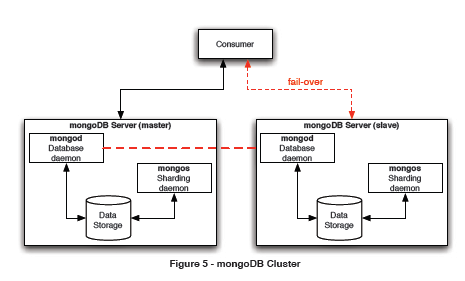
Figure 5 - MongoDB Cluster
A MongoDB cluster consists of a master and a slave. The slave may become the master in a fail-over scenario, if necessary. Having a master/slave configuration (also known as Active/Passive or A/P cluster) helps ensure data integrity since only the master is allowed to commit changes to the store at any given time. A commit is successful only if the data is written to GridFS and replicated in the slave

MongoDB also supports a limited master/master configuration. It's useful only for inserts, queries, and deletions by specific object ID. It must not be used if updates of a single object may occur concurrently.
Caching
MongoDB has a built-in cache that runs directly in the cluster without external requirements. Any query is transparently cached in RAM to expedite data transfer rates and to reduce disk I/O.
Document Format
MongoDB handles documents in BSON format, a binary-encoded JSON representation. BSON is designed to be traversable, lightweight and efficient. Applications can map BSON/JSON documents using native representations like dictionaries, lists, and arrays, leaving the BSON translation to the native MongoDB driver specific to each programming language.
BSON Example
{
'name' : 'Tom',
'age' : 42
}
| Language |
Representation |
| Python |
{
'name' : 'Tom',
'age' : 42
}
|
| Ruby |
{
"name" => "Tom",
"age" => 42
}
|
| Java |
BasicDBObject d;
d = new BasicObject();
d.put("name", "Tom");
d.put("age", 42);
|
| PHP |
array( "name" => "Tom",
"age" => 42);
|
Dynamic languages offer a closer object mapping to BSON/JSON than compiled languages.
The complete BSON specification is available from: http://bsonspec.org/
MongoDB Programming
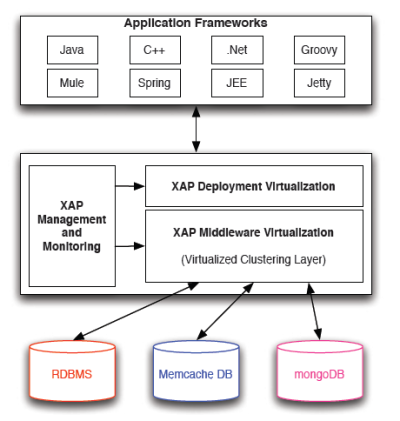
Programming in MongoDB requires an active server running the Mongod and the Mongos database daemons (see Figure 5), and a client application that uses one of the languagespecific drivers.

All the examples in this Refcard are written in Python for conciseness.
Starting the Server
Log on to the master server and execute:
[servername:user] ./Mongod
The server will display its status messages to the console unless stdout is redirected elsewhere.
Programming Example
This example allocates a database if one doesn't already exist,instantiates a collection on the server, and runs a couple of queries.
The MongoDB Developer Manual is available from:
http://www.Mongodb.org/display/DOCS/Manual
#!/usr/bin/env jython
import pyMongo
from pyMongo import Connection
connection = Connection('servername', 27017)
db = connection['people_database']
peopleList = db['people_list']
person = {
'name' : 'Tom',
'age' : 42 }
peopleList.insert(person)
person = {
'name' : 'Nancy',
'age' : 69 }
peopleList.insert(person)
# find first entry:
person = peopleList.find_one()
# find a specific person:
person = peopleList.find_one({ 'name' : 'Joe'})
if person is None:
print "Joe isn't here!"
else:
print person['age']
# bulk inserts
persons = [{ 'name' : 'Joe' }, {'name' : 'Sue'}]
peopleList.insert(persons)
# queries with multiple results
for person in peopleList.find():
print person['name']
for person in peopleList.find({'age' : {'$ge' : 21}}).sort('name'):
print person['name']
# count:
nDrinkingAge = peopleList.find({'age' : {'$ge' : 21}}).count()
# indexing
from pyMongo import ASCENDING, DESCENDING
peopleList.create_index([('age', DESCENDING), ('name', ASCENDING)])
The PyMongo documentation is available at: http://api.Mongodb.org/python - guides for other languages are also available from this web site.
The code in the previous example performs these operations:
- Connect to the database server started in the pr evious section
- Attach a database; notice that the database is tr eated like an associative array
- Get a collection (loosely equivalent to a table in a relational database), treated like an associative array
- Insert one or mor e entities
- Query for one or mor e entites
Although MongoDB treats all these data as BSON internally, most of the APIs allow the use of dictionary-style objects to streamline the development process.
Object ID
A successful insertion into the database results in a valid Object ID. This is the unique identifier in the database for a given document. When querying the database, a return value will include this attribute:
{
"name" : "Tom",
"age" : 42,
"_id" : ObjectId('999999')
}
Users may override this Object ID with any ar gument as long as it's unique, or allow MongoDB to assign one automatically.
Common Use Cases
- Caching - more robust capabilities, plus persistence, when compared against a pure caching system
- High volume processing - RDBMS may be too expensive or slow to run in comparison
- JSON data and program objects storage - many RESTful web services provide JSON data; they can be stored in MongoDB without language serialization overhead (especially when compared against XML documents)
- Content management systems - JSON/BSON objects can represent any kind of document, including those with a binary representation
MongoDB Drawbacks
- No JOIN operations - each document is stand-alone
- Complex queries - some complex queries and indices are better suited for SQL
- No row-level locking - unsuitable for transactional data without error prone application-level assistance
If any of these is part of the functional requirements, a SQL database would be better suited for the application.







{{ parent.title || parent.header.title}}
{{ parent.tldr }}
{{ parent.linkDescription }}
{{ parent.urlSource.name }}