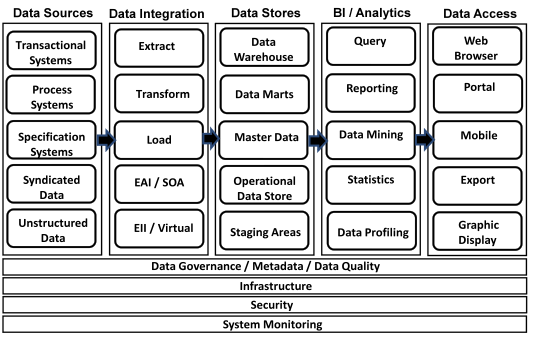
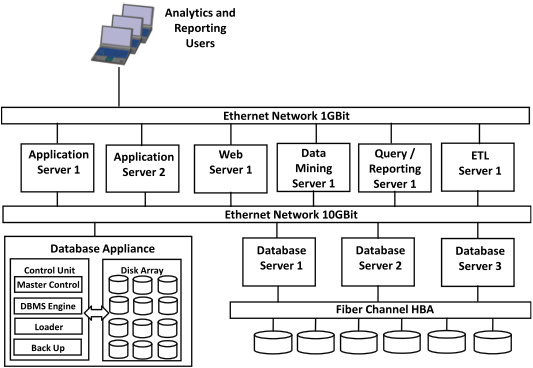
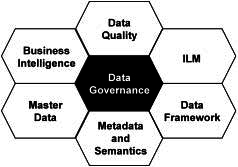
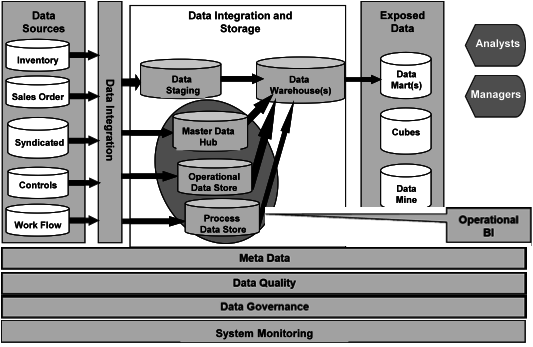
Data integration is a technique for moving data or otherwise making data available across data stores. The data integration process can include extraction, movement, validation, cleansing, transformation, standardization, and loading.
Extract Transform Load (ETL)
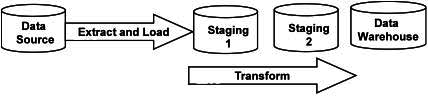
In the ETL pattern of data integration, data is extracted from the data source and then transformed while in flight to a staging database. Data is then loaded into the data warehouse. ETL is strong for batch processing of bulk data.

Extract Load Transform (ELT)
In the ELT pattern of data integration, data is extracted from the data source and loaded to staging without transformation. After that, data is transformed within staging and then loaded to the data warehouse.
Change Data Capture (CDC)
The CDC pattern of data integration is strong in event processing. Database logs that contain a record of database changes are replicated near real time at staging. This information is then transformed and loaded to the data warehouse.

CDC is a great technique for supporting real-time data warehouses.
Innovation in Data Warehouse Technology
Thanks to the agility offered by today’s cloud-based data warehouse solutions, there are cutting-edge innovations that can automate some of the key aspects of data warehousing. For example, the ETL process described earlier has changed considerably thanks to machine learning and natural language processing, ultimately resulting in its complete automation. What’s more, data warehouse storage and compute have also benefited from automated optimization, saving data analysts time on tasks associated with querying, storage, and scalability, which dramatically cuts down costs, coding time, and resources.
As a modern solution, cloud data warehouse automation saves endless hours of coding and modeling for data ingestion, integration, and transformation. The tasks listed below can be now easily automated and seamlessly connected to third-party solutions, such as business intelligence visualization tools, via the cloud:
- Automate data source connections.
- Seamlessly connect to third-party SaaS APIs.
- Easily connect to the most common storage services.
New technology now exists that automates data schema modeling, where adaptive schema changes at real time along with the data, and changes are seamless. You would only need to just upload the data sources, everything else is automated including the following tasks:
- Data types are automatically discovered, and a schema is generated based on the initial data structure.
- Likely relationships between tables are automatically detected and used to model a relational schema.
- Aggregations are automatically generated.
- Table history feature allows you store data uploaded from API data sources, so you can compare and analyze data from different time periods.
Automated Query Optimization
Automated cloud data warehousing technology exists that can automatically re-index the schema and perform a series of optimizations on the queries and data structure to improve runtime based on algorithms that assess usage so that:
- Re-indexing happens automatically whenever the algorithm detects changes in query patterns.
- Redistributing the data across nodes to improve data locality and join performance is done automatically.
Solving Concurrency Issues
To remedy concurrency issues, new cloud data warehousing technologies today can separate storage from compute and increase the compute nodes based on the amount of connections. Consequently, the number of available clusters scales with the number of users and the intensity of the workload, supporting hundreds of parallel queries that are load-balanced between clusters.
Storage Optimization
Data warehouse automation has also vastly improved how data is stored and used. New, “smart” data warehouse technologies constantly run periodic processes to mark data and optimize the storage based on usage. Smart data warehouse technology scales up and down based on the data volume. Scaling happens automatically behind the scenes, keeping clusters available for both reads and write, and thus ingestion can continue uninterrupted. When the scaling is complete, the old and new clusters are swapped instantly. In addition, the data warehouse maintenance itself has been greatly improved, as well, by automating the cleaning and compressing of tables to boost database performance.