What is Continuous Integration?
With the advent of lean, agile, and more recently, Continuous Delivery and DevOps, projects no longer incubate for months in a waterfall-like development process. Instead, they undergo constant changes and releases. In many cases, these projects are distributed throughout an organization at different stages of the development lifecycle.
This always-on development means the volume of changes alone necessitates an automated approach to building applications. To support developers at scale, several tools have been developed to automate much of what goes into building and releasing applications. This includes the ability to package applications or components generated during build, and do so continuously as changes are made. Colloquially this is referred to as Continuous Integration, or CI.
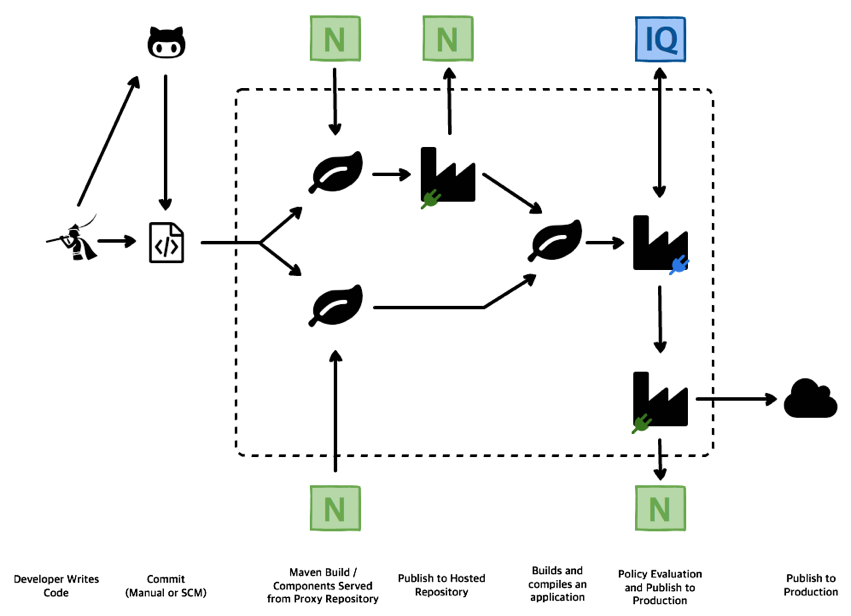
Pipeline
Building on the automation benefits from CI servers, teams are now able to completely customize what goes where, when, and how. In other words, teams add in various checkpoints throughout the process to ensure applications are free of major defects. This isn’t merely quality assurance anymore, but rather governance to avoid including vulnerability, license, and architectural issues in the applications and components a team is producing. The result is a pipeline-like approach.
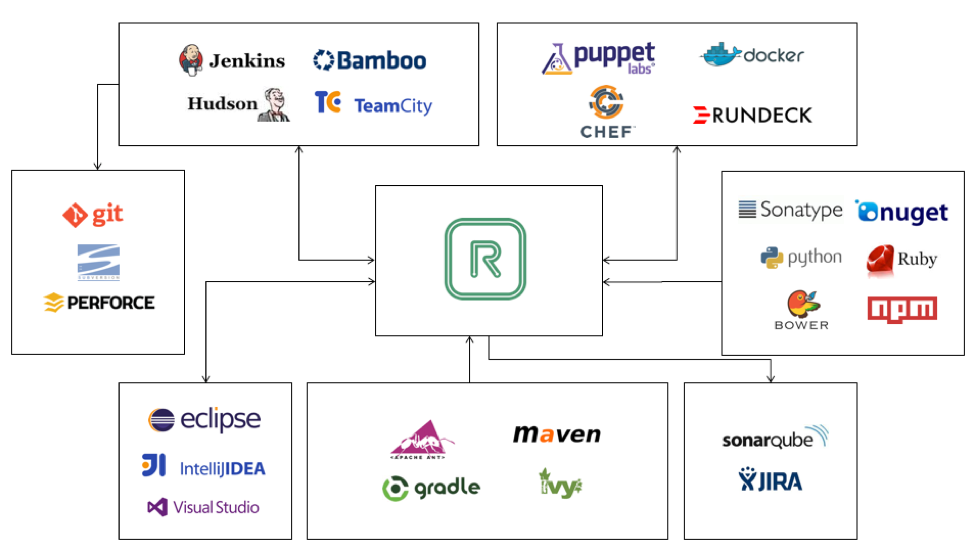
Repository Managers and CI Tools
Repository managers provide several interaction points with CI tools like Jenkins and Bamboo. This can range from simply requesting and storing a proxy of components as part of the build process, to publishing internally developed components for distribution across a development organization.
Building Projects
When an application is built using Maven (or similar build tools), it gathers the components from a specified location (configured via Maven settings) and compiles them. The end result can be an application, or even another binary or component. Jenkins provides automation for this by allowing the inclusion of a Maven build step for freestyle and multi-configuration projects. When the Build step is called, the Maven project will build, and if Maven has been configured to do so, it can request components from a Repository Manager. In a similar fashion, using Maven’s Deploy goal (Maven has goals such as clean, compile, test, package, install, deploy all of which are managed by plugins) components can be published as a build step to a desired location. It’s important to note that this is Maven functionality and not something unique to Jenkins or any other system.
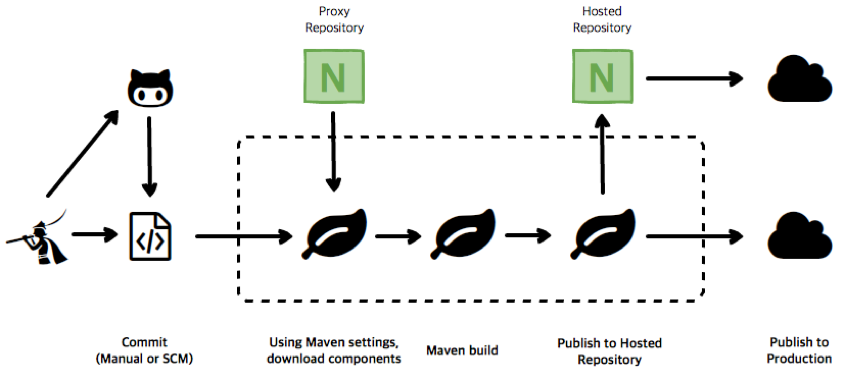
Publishing Projects
For teams moving into more advanced, continuous delivery and DevOps (Pipeline) models, Jenkins provides support for pipeline-style projects. This becomes less about simply building or compiling projects (à la Maven or similar tool), and more about automating tooling to take necessary action and/or get things where they need to be throughout the development lifecycle.
For example, it could be building a Maven package and making sure it’s published to a repository for testing, then removed once testing is complete. In more complex environments it likely means multiple builds are taking place simultaneously, and in parallel, then assembling each build together in a single package that is passed on through to staging and eventually into production. In some instances, the product of those builds is moved forward. In others, once it’s no longer needed it’s automatically removed.
The impact here is that it decouples the publishing process from the compilation tool, allowing greater customization and for components to be passed to the Repository Manager at any point in the development lifecycle, regardless of the development ecosystem.
Container Considerations
Docker containers and their usage have revolutionized the way applications and the underlying operating system are packaged and deployed to development, testing, and production systems. Docker Hub is the public registry for Docker container images and it is being joined by more and more other publicly available registries such as the Google Container Registry.
In many ways, a container is just like other components, with a few key differences:
- They can be huge. A Java component might be a few hundred kilobytes, but a container image can be many gigabytes or larger. This can put a strain on the underlying disk infrastructure if size and volume is not anticipated.
- They are comprised of many layers. Each layer is effectively a file system delta of changes upon the layers below it. This makes it interesting because all but the lowest level layer are unable to stand alone.
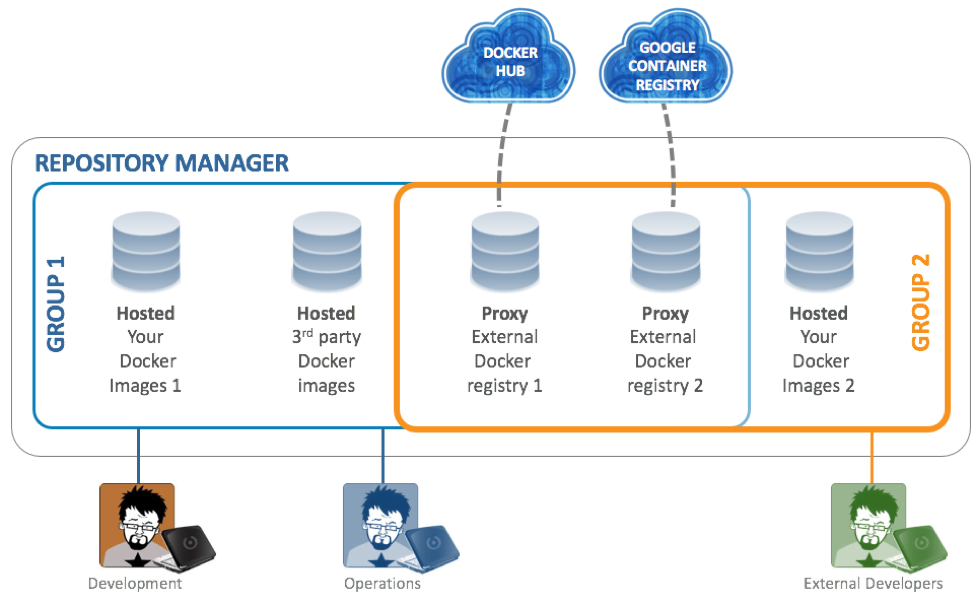
Repository Managers also offer support for Docker containers. The Repository Manager acts as a private Docker registry that is capable of hosting proprietary containers as well as proxying the public registries when non-proprietary containers need to be downloaded. You can expose these Docker repositories to the client-side tools directly or as a repository group, which is a repository that merges and exposes the contents of multiple repositories in one convenient URL.
This allows you to reduce time and bandwidth usage for accessing Docker images in a private registry as well as share proprietary images within your organization in a hosted repository. Users can then launch containers based on those images, resulting in a completely private Docker registry with all the features available in the Repository Manager.
Think of the Repository Manager as a heterogeneous location to store and manage your Docker images, open source software components, and other build artifacts. By comparison, other private container registry solutions act as homogeneous repositories.